上一篇文章實作了 Qdrant 向量資料庫,因為他免費加上可以本地假設的性質讓我選擇使用他。那今天就要來將 Embedding Model、Retriever、Qdrant、LLM 給結合起來,來讓 AI 可以透過 Retriever 的資料來回答他原本不知道的問題。
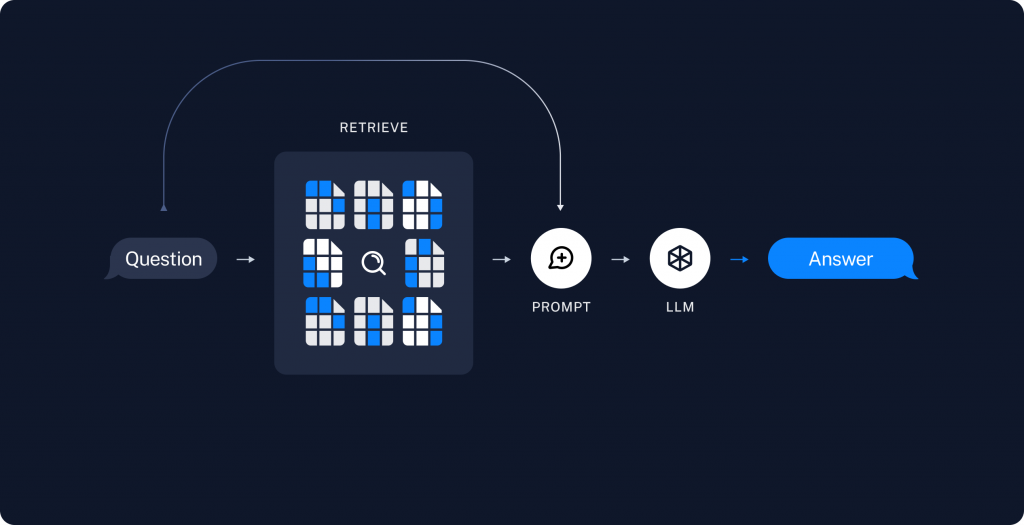
簡單來說,透過檢索資料生成回覆,這就是 RAG 的意思。上面這個圖很好的說明 RAG 的流程 (取自 LangChain):使用者輸入一個問題 -> 進入資料庫檢索 -> 將檢索的結果放入 Prompt 中 -> 將 Prompt 傳遞給 AI -> AI 生成結果,可以想像成向量資料庫是 AI 的 ChatGPT。
在實作之前,先再來了解兩個工具:
因為我們資料來源有很多種檔案可能,但是他可以幾乎可以解析當前最熱門的所有檔案格式,像是 PDF、TXT、Markdown、CSV、HTML、JSON。
由 Documents Loader 解析成字串之後,要藉由 TextSplitter 將內容隨機切割,若內容太長的話在可能丟給 AI 會超過 token 上限導致錯失重要內容,或者因為太多贅字而檢索到錯誤的內容。等等因素都證明 TextSplitter 是為了更精細地控制檢索和生成過程,從而提升 RAG 系統的準確性、效率和整體性能。
PDF 檔案連結 -> 高雄凱米颱風受災慰問補助說明.pdf
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 讀取 pdf
loader = PyPDFLoader("高雄凱米颱風受災慰問補助說明.pdf")
# 解析 pdf
docs = loader.load()
# 設定切割的長度
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
# 切割內容
splits = text_splitter.split_documents(docs)
# 查看切割後的結果
print(splits)
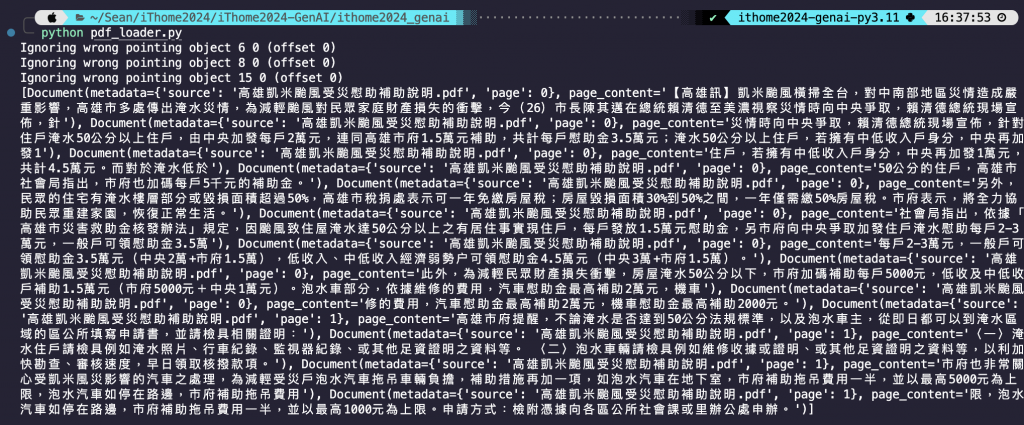
程式碼結果探討 🧐:
chunk_size,即代表 100 個字切割一次。然後有可能在重要的地方被切斷,所以 chunk_overlap 的設置會向前覆蓋,那我這邊是向前覆蓋 20 個字。根據我自己的經驗是大約取切割字數的 10% 上下差不多。from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 讀取 Web
loader = WebBaseLoader("https://www.businessweekly.com.tw/international/blog/3016080")
# 解析 Web
docs = loader.load()
# 設定切割的長度
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
# 切割內容
splits = text_splitter.split_documents(docs)
# 查看結果
print(splits)
程式碼結果探討 🧐:
這邊所使用的資料就是前面的 PDF 檔案和 HTML 網頁,向量資料庫為 Qdrant,LLM 為台智雲的 ffm-llama3-70b-chat,Embedding Model 也是台智雲的。
python version -> 3.11.7
langchain==0.2.14
langchain-core==0.2.33
langchain-community==0.2.12
langchain-qdrant==0.1.3
langchain-text-splitters==0.2.2
qdrant-client=1.11.0
python-dotenv==1.0.1
bs4==0.0.2
pypdf==4.3.1
requests==2.32.3
# 匯入套件
from langchain_ffm import ChatFormosaFoundationModel, FFMEmbedding
from langchain_qdrant import QdrantVectorStore
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.runnables import RunnablePassthrough, RunnableLambda, RunnableParallel
from langchain_core.prompts import PromptTemplate
from qdrant_client import QdrantClient
from qdrant_client.http import models
from qdrant_client.http.models import Distance
# 選擇模型和連線向量資料庫
llm = ChatFormosaFoundationModel(model="ffm-llama3-70b-chat", temperature=0.01)
embeddings = FFMEmbedding(model='ffm-embedding')
client = QdrantClient(url="http://localhost:6333")
collections_name = "rag_practice"
# 1.若 collection 存在則刪除 (現在沒有recreate函數)
if client.collection_exists(collection_name=collections_name):
client.delete_collection(collection_name=collections_name)
else:
pass
# 1.建立一個新的 collections
client.create_collection(
collection_name=collections_name,
vectors_config=
models.VectorParams(
size=1536,
distance=Distance.COSINE,
),
)
# langchain 連線 Qdrant 已存在的 collections
qdrant_vector_store = QdrantVectorStore.from_existing_collection(
url="http://localhost:6333",
collection_name=collections_name,
embedding=embeddings,
)
# 2.切割 html 內容的函數
def split_html(url, html_chunk_size, html_chunk_overlap):
html_loader = WebBaseLoader(url)
html_docs = html_loader.load()
html_text_splitter = RecursiveCharacterTextSplitter(chunk_size=html_chunk_size, chunk_overlap=html_chunk_overlap)
html_split = html_text_splitter.split_documents(html_docs)
return html_split
# 2.切割 pdf 內容的函數
def split_pdf(pdf_path, pdf_chunk_size, pdf_chunk_overlap):
pdf_loader = PyPDFLoader(pdf_path)
pdf_docs = pdf_loader.load()
pdf_text_splitter = RecursiveCharacterTextSplitter(chunk_size=pdf_chunk_size, chunk_overlap=pdf_chunk_overlap)
pdf_split = pdf_text_splitter.split_documents(pdf_docs)
return pdf_split
# 2.將切割的兩個函數透過平行運算的方式進行切割,速度會快一點
def split_parallel():
process = RunnableParallel({
"html": RunnableLambda(lambda inputs: split_html(inputs["url"], inputs["html_chunk_size"], inputs["html_chunk_overlap"])),
"pdf": RunnableLambda(lambda inputs: split_pdf(inputs["pdf_path"], inputs["pdf_chunk_size"], inputs["pdf_chunk_overlap"]))
})
results = process.batch([{
"url": "https://www.businessweekly.com.tw/international/blog/3016080",
"html_chunk_size": 1000,
"html_chunk_overlap": 100,
"pdf_path": "高雄凱米颱風受災慰問補助說明.pdf",
"pdf_chunk_size": 500,
"pdf_chunk_overlap": 50
}])
return results[0]['html'], results[0]['pdf']
# 2.取得切割結果
html_data, pdf_data = split_parallel()
# 3.將資料匯入 Qdrant 的函數
def data2qdrant(data):
qdrant_vector_store.add_documents(documents=data)
# 3.匯入資料庫一樣以平行運算的方式匯入
process = RunnableParallel({
"html_qdrant_vector_store": RunnableLambda(lambda inputs: data2qdrant(inputs["html_data"])),
"pdf_qdrant_vector_stroe": RunnableLambda(lambda inputs: data2qdrant(inputs["pdf_data"]))
})
process.batch([{"html_data": html_data, "pdf_data": pdf_data}])
# 4.指定 retriever
retriever = qdrant_vector_store.as_retriever()
# 4.RAG 的 prompt
template = """僅根據以下內容回答問題:
{context}
問題: {question}
"""
prompt = PromptTemplate.from_template(template)
# 4.將所有東西都 Chain 起來
chain = (
RunnableParallel({"context": retriever, "question": RunnablePassthrough()})
| prompt
| llm
)
# 5.透過 batch 方式一次傳多個問題取得想要的資訊
q1_for_olympics = "奧運男籃第一隊的球員有誰?"
q2_for_olympics = "奧運男籃的A,B,C組分別是哪些國家?"
q_for_typhoon = "淹水50公分以上住戶可以領多少錢?"
response = chain.batch([q1_for_olympics, q_for_typhoon, q2_for_olympics])
print(f"""Q: {q1_for_olympics}, \nA: {response[0].content}\n
Q: {q2_for_olympics}, \nA: {response[2].content}\n
Q: {q_for_typhoon}, \nA: {response[1].content}""")
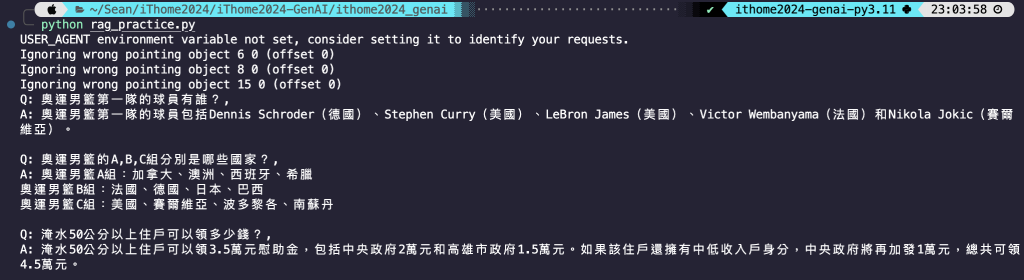
程式碼結果探討 🧐 (與註解編號一致):
chunk_size 設比較大,pdf 就設比較小。然後因為切割完一個資料再切割另一個資料,如果資料量多的話會很久,所以使用 LangChain LCEL 的架構的平行運算函數,可以同時進行切割。RunnablePassthrough,然後這個 query 同時也會傳去 Retriever,然後會回傳檢索的結果傳進 retriever 這個變數,這是 LCEL 的精髓所在。今天我們成功實作了 RAG 的功能,也成功使用到 LCEL 架構,也運用平行運算加速整個過程,也成功連結資料庫並檢索到正確的結果讓 AI 回答正確。透過這個實作更熟悉 LangChain 框架,還有 RAG 技術的應用,還蠻有成就感的☺️
Midjourney 有網頁版了!!

